Building a Job Scrapper
Building a Job Scrapper
특정 URL의 페이지를 페이스북에 포스트할 때 미리보기 이미지와 제목을 즉시 함께 포스트 한다. 어떻게 동작하는 것일까? URL의 웹 사이트를 스크랩핑해서 이미지와 제목을 읽어오는 것이다.
https://academy.nomadcoders.co/courses/681401/lectures/12171966
구글에서 검색할 때에도 마찬가지다. 구글은 페이지를 보여주면서 동시에 내용을 미리보기로 제공한다.
우리의 프로젝트는 이런 스크랩핑을 사용해서 스택 오버플로우에 있는 구인 페이지를 스크랩핑 하려 한다.
특정 단어로 검색하면 어마어마하게 많은 결과가 나오고 이것을 하나 하나 옮겨 적는 것은 많은 노력이 필요하다. 파이썬을 이용해서 페이지를 이동하며 게시물을 스크랩핑 하려 한다.
Navigating with Python
검색에 따른 많은 결과값이 있지만 한 페이지에 나타나는 내용은 한정되어 있다. 페이지를 이동하면서 스크롤링을 해야하는데, 한 페이지의 게시물의 수와 전체 페이지의 수를 안다면 도움이 된다.
먼저 페이지를 읽기 위해서 Requests 라이브러리를 사용하자.
왼쪽에 페키지 탭을 눌러 rqeusts 라이브러리를 설치하자
라이브러리를 추가하고 채용 페이지를 읽어보자 ```python
import requests
indeed_result = requests.get("https://kr.indeed.com/취업?q=python&limit=50")
print(indeed_result)
========================
<Response [200]>
```
여기에는 이 데이터를 text, json, html 등으로 변경해주는 기능이 같이 들어있다.
text로 찍어내면 상당히 어지럽고 복잡하다.
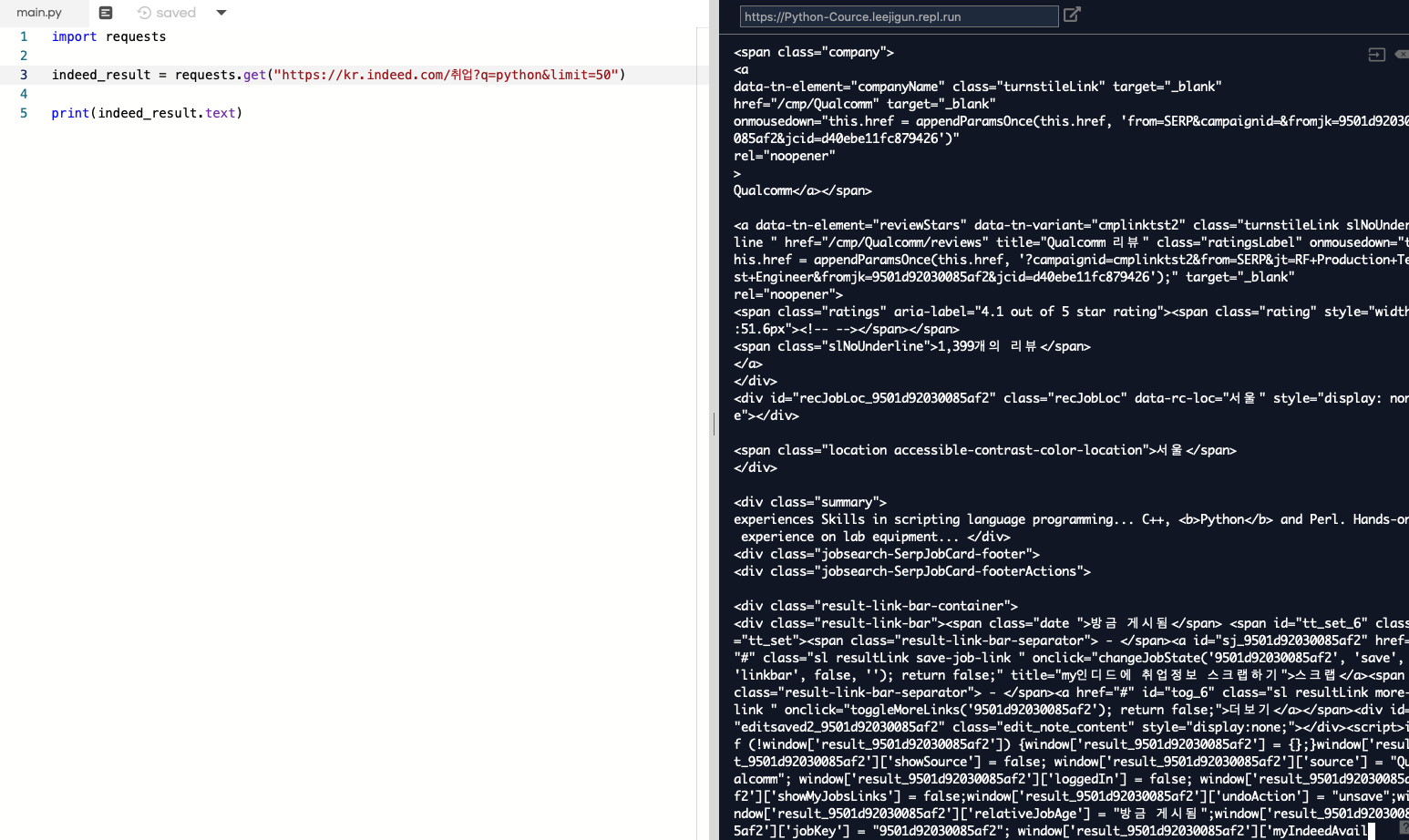
이를 보기 쉽게 하기 위해서 BeautifulSoup 라이브러리를 추가한다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/취업?q=python&limit=50")
soup = BeautifulSoup(indeed_result.text, 'html')
print(soup)
=========
.....
<div class="tellafriend-container result-tab email_job_content"></div>
<div class="sign-in-container result-tab"></div>
<div class="notes-container result-tab"></div>
</div>
</div>
<div class="jobToJobRec_Hide" id="jobToJobRec_f7c8a03dbcc659a7_sj"></div>
<div class="jobsearch-SerpJobCard unifiedRow row result" data-jk="4233609a843b5e96" data-tn-component="organicJob" id="p_4233609a843b5e96">
<div class="title">
<a class="jobtitle turnstileLink" data-tn-element="jobTitle"
href="/rc/clk?jk=4233609a843b5e96&fccid=aba87288e4cc3687&vjs=3"
id="jl_4233609a843b5e96"
onclick="setRefineByCookie([]); return rclk(this,jobmap[3],true,0);"
onmousedown="return rclk(this,jobmap[3],0);"
rel="noopener nofollow" target="_blank" title="분석지원팀 -데이터 분석가">
분석지원팀 - 데이터 분석가
</a>
</div>
<div class="sjcl">
<div>
<span class="company">
Nexon</span>
</div>
<div class="recJobLoc" data-rc-loc="성남 분당구" id="recJobLoc_4233609a843b5e96" style="display: none"></div>
<span class="location accessible-contrast-color-location">성남 분당구</span>
</div>
<div class="summary">
및 커뮤니케이션 능력 - (필수) 새로운 기술 습득에 능동적이고 거부감이 없는 분 - (선택) R 혹은 <b>Python</b>을 이용한 데이터분석 능력 - (선택) SQL 기본 활용 능력 - (선택) 통계 및 분석에 대한 이론... </div>
<div class="jobsearch-SerpJobCard-footer">
<div class="jobsearch-SerpJobCard-footerAc
.......
뷰티풀스프의 문서를 살펴보면 html을 파싱하는 여러가지 방법들을 제공한다.
html의 특정 컴포넌트를 뽑아오거나 제목만 추출하는 기능들을 제공한다.
여기서는 페이지 네비게이션 컴포넌트를 추출해보자.
해당 페이지를 크롬 개발자 모드로 뜯어보면 네비게이션 부분을 찾을 수 있다. 이 부분만 뽑아내보자.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/취업?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, 'html')
pagination = indeed_soup.find('div', {'class': 'pagination'})
print(pagination)
이제 여기서 각각의 페이지로 이동하는 링크들만 추출해보자. <a> 태그를 가진 부분만 꺼내면 된다.
# 각각의 페이지 링크들만 꺼냄
pages = pagination.find_all('a')
print(pages)
이제 a 태그를 지닌 페이지 배열이 완성된다. 여기서 url만 페이지 번호만 꺼내려면 span 태그로 감싼 부분을 꺼내면 된다.
# 각각의 페이지 링크들만 꺼냄
pages = pagination.find_all('a')
for page in pages:
print(page.find('span'))
======
<span class="pn">2</span>
<span class="pn">3</span>
<span class="pn">4</span>
<span class="pn">5</span>
<span class="pn">6</span>
<span class="pn">7</span>
<span class="pn">8</span>
<span class="pn">9</span>
<span class="pn">10</span>
<span class="pn"><span class="np">다음 »</span></span>
여기서 함수형을 조금 추가하고 페이지의 숫자들만 저장하고 마지막 페이지를 뽑아보자.
# 각각의 페이지 링크들만 꺼냄
pages = pagination.find_all('a')
# 각 페이지에서 숫자만 뽑아내고
spans = (int(span) for span in (page.find('span').string for page in pages))
# 마지막 페이지 숫자를 추출해 최대값을 꺼낸다.
max_page = spans[-1]
다음 페이지는 무시한다.
이제 최대 페이지를 알았으니까 반복해서 페이지를 호출할 수 있게 되었다.
함수형 프로그래밍
함수형으로 마지막 페이지 값을 꺼내는 함수를 만들었다.
INDEED_URL = "https://kr.indeed.com/취업?q=python&limit=50"
def extract_indeed_pages() -> int:
result = requests.get(INDEED_URL)
soup = BeautifulSoup(result.text, features="html.parser")
# 화면에서 페이지 네비게이션을 생성
pagination = soup.find('div', {'class': 'pagination'})
# 각각의 페이지 링크들만 꺼냄
pages = pagination.find_all('a')
pages_iter = iter(pages)
# 페이지 넘버만 꺼냄
string_spans = map(lambda page: page.find('span').string, pages_iter)
# int로 형변환 (이 과정에서 '다음' 문구 제거)
optional_int_spans = map(lambda string: optional_casting(string), string_spans)
# None 값 제거
nonNull_spans = filter(lambda value: value is not None, optional_int_spans)
# 마지막 페이지값 꺼냄
max_page = fp.reduce(lambda last, value: max(last, value), nonNull_spans, 0)
return max_page
# 숫자 string을 int로 안전하게 변환
def optional_casting(string) -> int:
try:
return int(string)
except ValueError:
return None
이 내용을 다른 파일로 분리해서 모듈화시키면 다음과 같이 사용 가능하다.
#main.py
from scraping.indeed import extract_indeed_pages
max_indeed_pages = extract_indeed_pages()
print(max_indeed_pages)
================================================
11
indeed 페이지를 보면 2페이지로 넘어간 URL은 start=50으로 시작한다. start=0은 1페이지로 특정 값부터 시작해서 limit값까지의 데이터를 읽는 형태로 되어있다.
저 start값을 변경해서 반복적으로 모든 페이지를 가져올 수 있다. 일단 status_code를 찍어보자.
def extract_indeed_jobs(last_page):
for page in range(last_page):
result = requests.get(f'{URL}&start={page * LIMIT}')
print(f'{page}: {result.status_code}')
=========================================================
0: 200
1: 200
2: 200
3: 200
4: 200
5: 200
6: 200
7: 200
8: 200
9: 200
10: 200
이제 실제 데이터의 하나의 셀을 뜯어보자
저 안에서 ‘title’ 클래스 안에 있는 속성의 title의 값을 꺼냅니다.
def extract_indeed_jobs(last_page):
for page in range(last_page):
result = requests.get(f'{URL}&start={page * LIMIT}')
soup = BeautifulSoup(result.text, features="html.parser")
#'jobsearch-SerpJobCard' 카드의 키값
cells = soup.find_all('div', {'class':'jobsearch-SerpJobCard'})
for cell in cells:
title = cell.find('div',{'class':'title'}).find('a')['title']
print(f'{page}: {title}')
============================================================================
...
7: Researcher(AI/Deep Learning)
7: Field Application Engineer (FAE)
7: Smart Manufacturing Data Scientist
8: 프로그래머, 개발자
8: 컨설팅회사 분야별(PMO,PI,ISP, Data Analytics등)컨설턴트 포지션 asap
8: Data Scientist
8: RF Layout CAE 4G LTE 5G NR Software Engineer
8: Principal, Business Analysis (Retail Systems)
8: SW개발자 (경력 3년이상)
...
같은 방법으로 회사명도 출력한다.
def optional_casting_srt(any) -> str:
if any == None:
return ''
try:
return str(any)
except ValueError:
return ''
company = cell.find('div',{'class': 'sjcl'}).find('span',{'class':'company'}).string
compnayName = optional_casting_srt(company).strip()
print(compnayName)
회사명, 지역, 링크를 추출하도록 함수화 한다.
import requests
import functools as fp
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://kr.indeed.com/취업?q=python&limit={LIMIT}"
def extract_indeed_pages() -> int:
result = requests.get(URL)
soup = BeautifulSoup(result.text, features="html.parser")
# 화면에서 페이지 네비게이션을 생성
pagination = soup.find('div', {'class': 'pagination'})
# 각각의 페이지 링크들만 꺼냄
pages = pagination.find_all('a')
pages_iter = iter(pages)
# 페이지 넘버만 꺼냄
string_spans = map(lambda page: page.find('span').string, pages_iter)
# int로 형변환 (이 과정에서 '다음' 문구 제거)
optional_int_spans = map(lambda string: optional_casting(string), string_spans)
# None 값 제거
nonNull_spans = filter(lambda value: value is not None, optional_int_spans)
# 마지막 페이지값 꺼냄
max_page = fp.reduce(lambda last, value: max(last, value), nonNull_spans, 0)
return max_page
def extract_indeed_jobs() -> list:
last_page = extract_indeed_pages()
for page in range(last_page):
result = requests.get(f'{URL}&start={page * LIMIT}')
soup = BeautifulSoup(result.text, features="html.parser")
#'jobsearch-SerpJobCard' 카드의 키값
cells = soup.find_all('div', {'class':'jobsearch-SerpJobCard'})
return list(map(lambda cell: extract_job_dic(cell), cells))
def extract_job_dic(cell) -> dict:
title = cell.find('div',{'class':'title'}).find('a')['title']
company = exteract_compny_name(cell)
location = exteract_location(cell)
link = exteract_link(cell)
return {'title': title, 'company': company, 'location': location, 'link': link}
#제목 추출
def extreact_title(cell) -> str:
return cell.find('div',{'class':'title'}).find('a')['title']
# 회사 이름 추출
def exteract_compny_name(cell) -> str:
# 회사 이름이 표시되는 방식이 2가지
company = cell.find('div',{'class': 'sjcl'}).find('span',{'class':'company'})
if company.find('a') != None:
compnayName = company.find('a').string
else:
compnayName = ''
company_string = optional_casting_srt(company.string).strip()
compnayName = optional_casting_srt(compnayName).strip()
# 별점이 붙은 회사 이름이 있는데 그것 때문에 2가지 타입으로 뽑아내야함
if compnayName != '':
return compnayName
else:
return company_string
# 위치값 뽑아오기
def exteract_location(cell) -> str:
return cell.find('div',{'class': 'sjcl'}).find('div', {'class': 'recJobLoc'})['data-rc-loc']
#이동 링크 뽑아오기
def exteract_link(cell) -> str:
id = cell.find('div',{'class':'title'}).find('a')['id']
id = str(id).replace('jl_','')
return f'https://kr.indeed.com/채용보기?jk={id}'
# 숫자 string을 int로 안전하게 변환
def optional_casting(string) -> int:
try:
return int(string)
except ValueError:
return None
def optional_casting_srt(any) -> str:
if any == None:
return ''
try:
return str(any)
except ValueError:
return ''
파일에 저장한다.
import csv
def save_to_file(jobs):
# 파일 열기, 없으면 생성
file = open('jobs.csv', mode = 'w')
writer = csv.writer(file)
writer.writerow(['title', 'company', 'location', 'link'])
for job in jobs:
writer.writerow(list(job.values()))
return